Putting AI to the Clinical Test
A study published in Nature Medicine has subjected OpenAI's ChatGPT to a structured evaluation of its ability to make medical triage recommendations — the critical first step in emergency care where patients are sorted by the urgency of their condition. The research represents one of the most methodologically rigorous assessments to date of whether large language models can perform reliably in clinical settings where errors can have life-or-death consequences.
Triage is a particularly challenging test for AI systems because it requires integrating multiple streams of information — reported symptoms, patient history, vital signs, and contextual cues — to make rapid judgments about how urgently a patient needs care. Getting it wrong in either direction carries serious risks: under-triaging a critical patient can lead to delayed treatment and preventable death, while over-triaging a stable patient wastes scarce emergency resources.
Study Design and Methodology
The researchers designed a structured test using standardized clinical vignettes — detailed written descriptions of patient presentations that are commonly used in medical education and board examinations. Each vignette included information about the patient's presenting complaint, relevant medical history, vital signs, and physical examination findings.
ChatGPT was asked to assign each case to one of five standard triage categories, ranging from immediate life-threatening emergencies requiring instant intervention to non-urgent conditions that could safely wait for routine care. The AI's recommendations were then compared against consensus triage assignments made by experienced emergency medicine physicians.
The study controlled for several variables that have complicated previous evaluations of AI medical performance. Prompt engineering was standardized to eliminate variation in how questions were posed to the model. Multiple runs were conducted to assess consistency, and the researchers analyzed not just the accuracy of the final triage assignment but also the reasoning provided by the model.

Key Findings
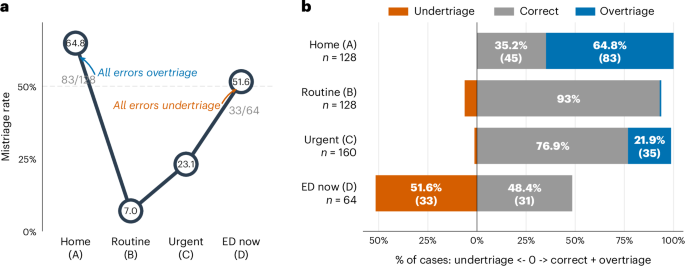
The study found that ChatGPT performed with mixed results across different levels of acuity. For the most critical cases — patients presenting with clear life-threatening emergencies such as cardiac arrest, major trauma, or severe respiratory distress — the model generally performed well, correctly identifying the need for immediate intervention in the majority of cases.
However, performance degraded in the middle triage categories, where the distinction between urgent and semi-urgent cases requires more nuanced clinical judgment. These are precisely the cases where triage errors are most common even among experienced clinicians, and where the consequences of misclassification are most clinically significant.
The model also exhibited inconsistency across repeated evaluations of the same cases. When presented with identical clinical vignettes multiple times, ChatGPT sometimes assigned different triage categories, a finding that raises concerns about the reliability of LLM-based clinical tools in real-world settings where consistency is essential.
- ChatGPT performed best on clearly critical cases but struggled with nuanced middle-acuity triage decisions
- The model showed inconsistency when presented with identical cases multiple times
- Reasoning quality varied significantly, with some assessments demonstrating sound clinical logic and others reflecting apparent confabulation
- The study used standardized vignettes and controlled prompting to ensure rigorous evaluation
Implications for Healthcare AI
The findings have significant implications for the growing movement to integrate AI into healthcare workflows. Proponents of medical AI argue that large language models could help alleviate the severe shortage of emergency physicians and triage nurses, particularly in under-resourced healthcare settings and developing countries where access to trained medical professionals is limited.
The study suggests that while ChatGPT may be useful as a supplementary tool — helping clinicians think through differential diagnoses or flagging potentially overlooked considerations — it is not yet reliable enough to serve as an autonomous triage system. The inconsistency in repeated evaluations is particularly concerning, as clinical decision support tools need to produce the same recommendation given the same inputs.
The researchers note that their findings apply specifically to the version of ChatGPT tested and that model capabilities are evolving rapidly. Newer models with enhanced reasoning capabilities and medical fine-tuning may perform significantly better. However, they caution against deploying any AI system in clinical triage without extensive validation against real-world patient outcomes, not just standardized test cases.

The Regulatory Question
The study also highlights the challenge facing regulators as AI tools increasingly find their way into clinical practice. In many countries, medical decision support software is subject to regulatory approval as a medical device. However, the rapid pace of AI model updates — with new versions released every few months — creates a regulatory challenge, as each update could potentially alter the system's clinical performance.
The U.S. Food and Drug Administration has been developing a framework for regulating AI-based medical devices, including provisions for continuous learning systems that evolve over time. But the framework remains a work in progress, and the gap between the speed of AI development and the pace of regulatory adaptation continues to widen.
Looking Forward
The Nature Medicine study contributes to a growing body of evidence suggesting that large language models show genuine promise in medical applications but are not yet ready for autonomous clinical deployment. The path forward likely involves carefully designed human-AI collaboration systems where the model's recommendations are always subject to human review, combined with ongoing monitoring of clinical outcomes to ensure that AI assistance is actually improving patient care rather than introducing new risks.
For emergency departments already struggling with overcrowding and staffing shortages, even an imperfect AI tool that catches some missed critical cases could save lives. But deploying such a tool responsibly requires the kind of rigorous, structured evaluation exemplified by this study — not just demonstrations of impressive performance on cherry-picked examples.
This article is based on reporting by Nature Medicine. Read the original article.

Originally published on nature.com