
世界モデルは記憶の問題に直面している
動画生成システムは急速に進歩したが、ひとつの弱点は依然として残っている。時間がたつと、物理的な空間の把握を失いやすいことだ。カメラを向け直すと部屋の形が変わる。家具が移動する。表面が、モデルが少し前に示したものと一致しなくなる。この失敗は、とりわけ「世界モデル」と呼ばれる用途では大きな制約になる。そこでは、単発の見た目の美しさよりも連続性のほうが重要だからだ。
Microsoft Researchと大学の共同研究者らが開発したMirageという新しいシステムは、この問題により効率的に対処する手段として提示されている。従来のピクセルベースの3Dメモリパイプラインに頼るのではなく、Mirageはシーン情報をモデルの潜在空間に直接保存する。その結果、元資料によれば、長いカメラ移動でもより安定した空間的一貫性が得られ、速度とメモリ効率も大きく向上する。
このプロジェクトが際立つのは、生成シミュレーションにおける実用上のボトルネックのひとつ、つまり視点が変わるたびに過大な計算コストを払わずに場所を記憶する方法に取り組んでいる点だ。
従来のメモリパイプラインが高価な理由
多くの既存システムでは、空間記憶は可視画像データから構築した3D点群によって維持される。モデルが新しい視点を生成するたびに、その点群を更新し、さらに生成器が使える形へ何度も再レンダリングする。これにより、情報が潜在特徴からピクセル空間の構造へ移り、また戻るというループが生じる。
Mirageの著者はこの手法を二重のボトルネックだと述べている。計算コストが高いだけでなく、レンダリング画像空間を繰り返し行き来する過程で情報が失われるおそれもある。長い系列では、その損失が蓄積して目に見える不安定さにつながる。モデルは局所的にはもっともらしいフレームを出しながら、徐々に保持すべきシーンの幾何からずれていく可能性がある。
これは、世界モデルがシミュレーション、身体性を持つAIの訓練、合成環境、対話的なシーン生成のためのツールとしてますます注目されているからこそ重要だ。こうした場面では、記憶は任意ではない。角の向こうに何があるかを忘れるモデルは、長時間にわたって信頼できる環境モデルとして機能できない。

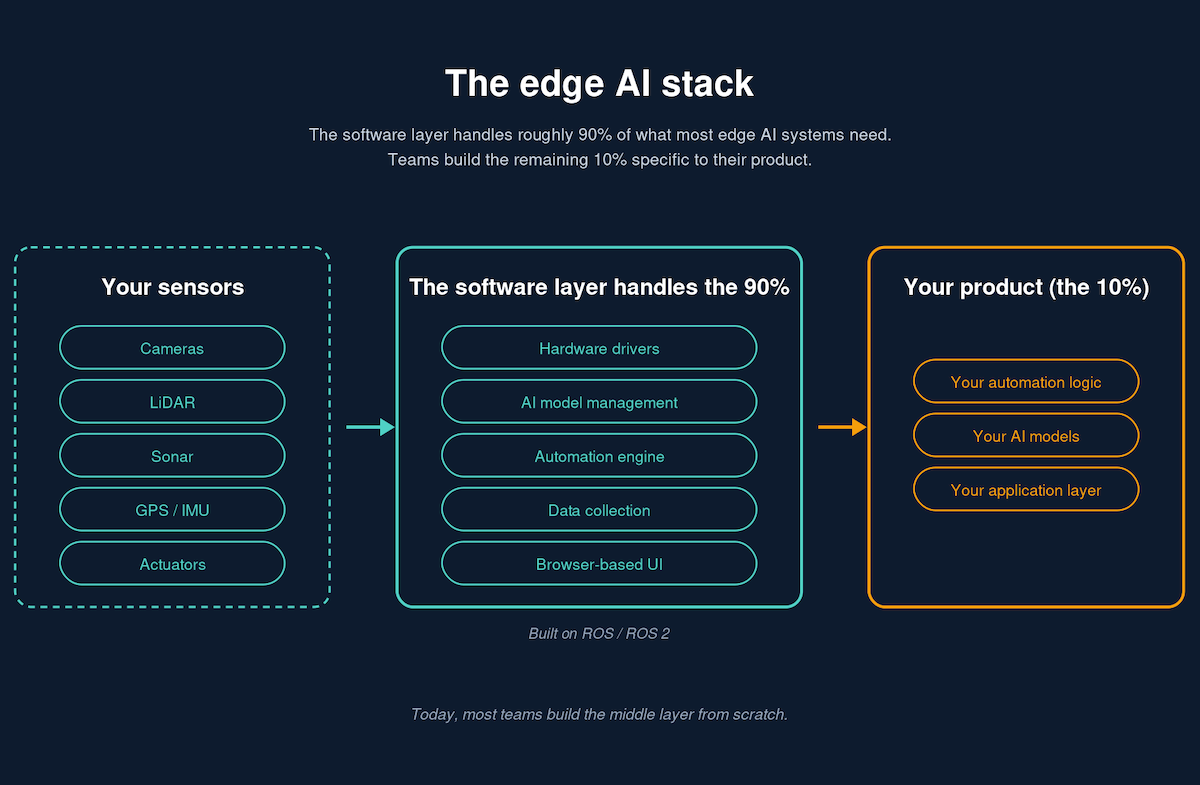
Mirageの核となる考え方
Mirageは、内部の画像特徴を潜在空間内の空間メモリへ直接保存するという別の道を取る。可視的な色の点だけを保持するのではなく、学習された特徴を3D空間上の位置に固定する。システムが新しい視点を生成する必要があるとき、その潜在メモリを対象カメラビューへ投影し、その結果をそのまま生成器に戻す。
ピクセル空間の点群をレンダリングし、再エンコードする寄り道を避けることで、Mirageは時間とメモリの両方を節約する設計になっている。元テキストによれば、類似モデルと比べて最大10.5倍高速に動画を生成し、最大55分の1のメモリで動作できるという。こうした改善は、手法が研究上の興味にとどまるか、実運用で有用になるかを左右しうる。
このアプローチは、生成AI全般に見られる広い流れとも一致する。重要な表現処理を、単なる生のピクセルよりもコンパクトで意味的に豊かな特徴を扱える潜在空間へと移していく流れだ。
このシステムが改善しそうな点
Mirageの中心的な約束は、効率だけではない。持続性だ。このモデルは、長いカメラ軌道の途中でも生成されたシーンの空間構造を一貫して保つことを意図しており、同じ視点が再び現れたときに内容が変質してしまう傾向を抑える。これは、シーンの連続性が付加価値ではなく課題そのものの一部である用途に特に重要だ。
重要なのは、元ソースが動く物体は依然としてメモリから除外されていると述べている点だ。これは、Mirageが現在のところ、複数の物体が時間とともに独立して動く動的環境を完全にモデル化することよりも、安定した静的シーン配置の維持に重点を置いていることを示唆する。それでも静的な世界を安定化することは、問題の基盤部分に対処する大きな一歩だ。
建築、部屋の配置、地形の幾何を一貫して記憶できる世界モデルは、将来的に、より洗練された動きや相互作用の扱いを取り込むシステムの強固な土台になる。

動画生成デモを超えて重要な理由
生成動画の研究は短いクリップや視覚的な見栄えで語られがちだが、より重要な進展はシミュレーションを支えるシステムから生まれるかもしれない。AIモデルをロボット、仮想エージェント、計画システム、インタラクティブなコンテンツツールの訓練環境として使うなら、何らかの形で持続する世界状態が必要になる。

そこにMirageの注目点がある。シーン記憶を、フレームごとの予測から生じる壊れやすい副産物ではなく、内部の構造化された資源として扱うモデル群への道筋を示している。効率的な空間記憶は、印象的な一回限りの生成と再利用可能なシミュレーション環境の間のギャップを埋める助けになる。
インフラの観点もある。計算コストは依然としてAI展開の主要な制約のひとつだ。処理時間とメモリ要件の両方を減らす手法は、高度な世界モデルを試せる研究者や企業の数を広げる。効率改善は、品質改善と同じくらい採用を左右することが多い。
注目すべき研究シグナル
Mirageはまだ、完成したプラットフォームではなく研究開発の段階として理解すべきだ。公開されている材料は、大規模展開よりも、そのアーキテクチャとベンチマーク上の優位性に焦点を当てている。アプローチがどの程度一般化するのか、より複雑または動的なシーンでどう機能するのか、下流のシミュレーション課題とどう統合されるのかは、なお不明だ。
しかし、この論文の方向性は重要だ。動画のリアリズムを、より大規模で力任せな生成によって追うのではなく、Mirageはモデルが空間を表現する方法にある構造的な弱点を突いている。信頼できる記憶は、クリップ生成機ではなく世界として機能したいモデルの前提条件だからだ。
実用面では、このシステムは、長期にわたるシーンの一貫性が高価なピクセル空間メモリループに依存する必要はないことを示唆している。より軽量な潜在空間の仕組みでも、より少ないコストでより多くの世界を保持できるかもしれない。
AI研究にとって、この組み合わせは強力だ。整合性が高まれば、世界モデルはより有用になる。コストが下がれば、よりスケーラブルになる。Mirageの主張がより広い検証でも成り立つなら、次世代の動画・シミュレーションモデルが最も難しい問題のひとつ、つまり「自分がどこにいるのかを記憶すること」の扱い方に影響を与えるかもしれない。
この記事はThe Decoderの報道をもとにしています。元記事を読む。
Originally published on the-decoder.com